2018上半年互联网恶意爬虫分析 从全景视角看爬虫与反爬虫的攻防博弈
在2018年上半年,随着互联网信息服务的高速发展与数据价值的日益凸显,恶意网络爬虫活动呈现出复杂化、规模化与隐蔽化的趋势。这不仅对各类网站的正常运营构成了严峻挑战,也引发了关于数据安全、用户隐私与网络公平性的广泛讨论。本文将从全景视角出发,深入剖析这一时期恶意爬虫的演变态势,并探讨爬虫与反爬虫技术在这场永不停息的攻防博弈中所扮演的角色。
一、恶意爬虫的演变与主要特征
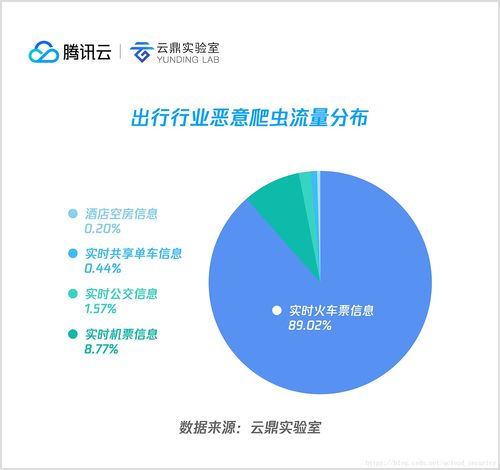
2018年上半年,恶意爬虫已不再是简单的数据抓取工具。其攻击目标从公开信息扩展到需登录访问的深层内容、API接口乃至移动应用数据。在技术上,爬虫广泛采用分布式代理IP池、模拟真人浏览行为(如鼠标移动、随机延迟)、破解JavaScript渲染以及绕过验证码等手段,以规避基础的反爬策略。电商平台的价格与库存信息、社交媒体的用户关系与内容、在线旅游的航班票价、金融信贷数据等成为高价值目标。这类爬虫活动往往以高频请求发起攻击,轻则导致服务器资源过载、响应迟缓,重则窃取核心商业数据或批量注册垃圾账号,直接损害企业利益与用户体验。
二、爬虫与反爬虫的对抗全景
面对日益猖獗的恶意爬虫,互联网信息服务提供者构筑了多层次、动态化的防御体系。技术层面,基础措施包括通过User-Agent识别、请求频率限制(Rate Limiting)和IP封禁来拦截低阶爬虫。更高级的防御则依赖于行为分析(如检测异常点击流模式)、验证码挑战(从图形到滑动、点选等交互式验证)、数据加密与混淆(如对关键接口返回数据进行动态编码),以及利用机器学习模型实时识别恶意流量。法律与协议层面,通过《网络安全法》等法规的约束及Robots协议的明确声明,也为数据爬取划定了合法边界。攻防双方始终处于动态博弈中。爬虫方不断进化其伪装与破解能力,甚至出现专门提供“反反爬虫”服务的灰色产业链;而防御方则持续迭代风控模型,尝试从单纯技术拦截转向“识别-监控-处置”的全流程管理。
三、影响与未来展望
恶意爬虫的泛滥深刻影响了互联网生态。一方面,它推高了企业的运营与安防成本,可能导致创新受阻;另一方面,个人隐私泄露风险加剧,数据滥用问题凸显。2018年上半年的态势表明,纯粹的技术对抗已难以根治问题,需构建技术、法律与行业自律协同的治理框架。随着人工智能在攻防两端的深化应用,爬虫可能更加智能地模拟人类,而防御系统也将更加精准、自适应。数据产权与合规使用的共识将日益重要,促使爬虫技术向合法、可控的领域发展,如公开数据的研究索引、搜索引擎优化等,最终推动互联网信息服务在开放与安全之间找到可持续的平衡点。
如若转载,请注明出处:http://www.hnmlbanai.com/product/53.html
更新时间:2026-06-18 09:20:39